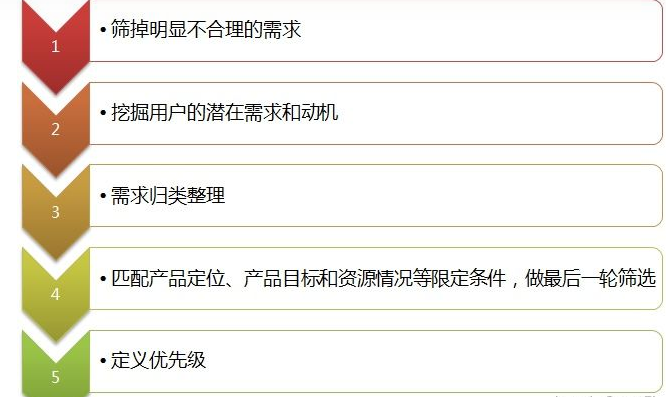
浅谈需求分析方法论
(1)产品初期(0-1):做最小可行产品(Minimum Viable Product,简称MVP),满足用户核心需求,快速上线,快速迭代。积累种子用户。此时产品不宜做得大而全,方便调整产品方向。如果是内容型产品,还需运营好社区基调,控制用户导入,比如知乎早期采用的邀请制。 (2)成长期:继续打磨核心需求,完善功能短板,让产品朝着指定方向发展。这时候会加大运营投入,用户大量导入,需求激增。这时候团队压力很大,要控制好需求,把握好核心用户,把资源用在刀刃上。同时重点关注留存和活跃,提高粘性和使用时长。 (3)产品成熟期:不断打磨产品,巩固产品壁垒,制造兴奋性需求,挖掘潜在用户,扩大用户规模。同时要开始考虑变现。
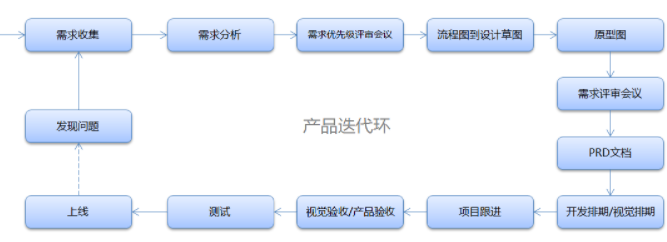
从需求到落地,产品全链路实现流程
设计原型前,先进行结构层和框架层的设计。也就是流程图到设计草图(纸面原型)。这一步不能跳过,前期考虑周全,会节约大量的时间,避免后面修改起来牵一发而动全身。 这个环节很多同学会去研究竞品或者寻找相似设计,这本身没什么错,但最好不要这样。容易固化思维。

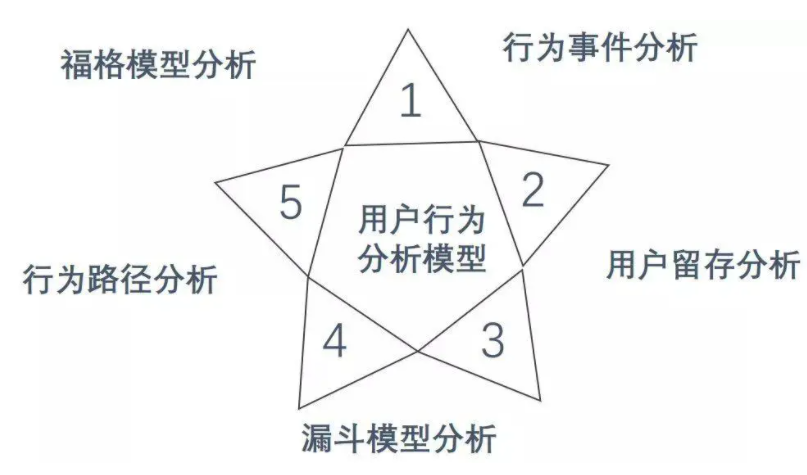
用户研究需求分析的常用六种方法
从流量营销到数据驱动,很多产品的精细化运营都是围绕用户来进行的,关键在于用户研究。 用户研究的常用方法有:情境调查、用户访谈、问卷调查、A/B测试、可用性测试与用户行为分析。其中用户行为分析是用户研究的最有效方法之一。
高级产品经理都在用的需求分析方法
第一性原理是一种从问题源头进行思考的意识或方法,好的产品经理可以将其纳入所有的思考过程。 也可以理解为是一种探寻根源的方法。常用的方式是连环追问法,它是一种以找出回答的有效信息,再以有效信息为线索进行连环追问的方法。 产品经理有两个核心的职责:一是探寻需求本质,二是解决问题。下面就来说一说怎样运用第一性原理来定位需求本质。
从社交软件中找寻用户的真正需求?
实证已经是一门非常成熟的研究方法,早已被用在了很多领域,比如实证医学、实证经济学等等。对社交产品实证研究更偏向实证主义社会学,更注重经验调查和社会调查,但实证产品分析方法更要注重对现象、线索的发掘、然后再理解、解构,最后重构的循环过程。
需求分析师应具备的几项能力
1、沟通能力: 1)与客户:通过与客户交谈,挖掘本质需求。 举例:有时候客户会提出增加一个字段,一线的实施人员或销售人员没有问清楚为什么要加这个字段,就直接反馈给需求人员。无论是做项目,还是做产品,都要求需求人员要了解客户需求的本质,要多问为什么,什么样的业务场景下会用到这个需求,一定要打破砂锅问到底,如果一线人员表达不清楚,宁可不要做。
需求分析师-一个门槛不低的职位
一、深刻理解业务 二、充分和用户沟通 三、具备深厚的技术背景和严谨的思维 一看上面这个三点,就觉得门槛不低了,何况要全面,更怕业务涉及一大堆方向。。。
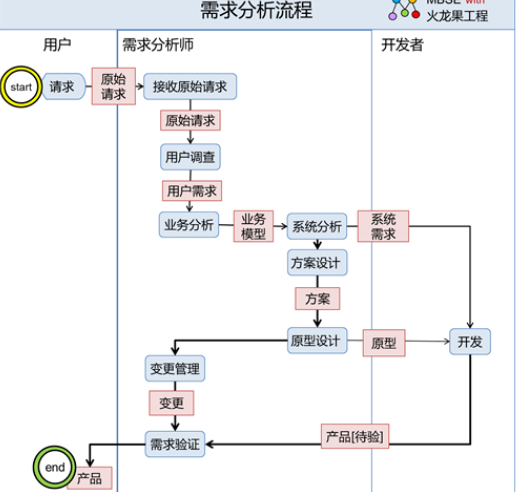
用户需求说明书_需求分析师能力模型
需求分析师一般由具有业务背景经验的技术人员担任,在不同的企业,这个角色的名称不一样,有的企业叫做 BA(业务分析师),有的企业叫做SA(系统分析师)。前者更侧重业务分析、后者更侧重系统分析。需求人员目前存在的主要问题是不清楚需求有哪些内容和层次,需求工作太被动,主要是等待用户提出需求,对需求缺乏系统的分析和长远的规划。造成需求变更出现的时候疲于奔命。
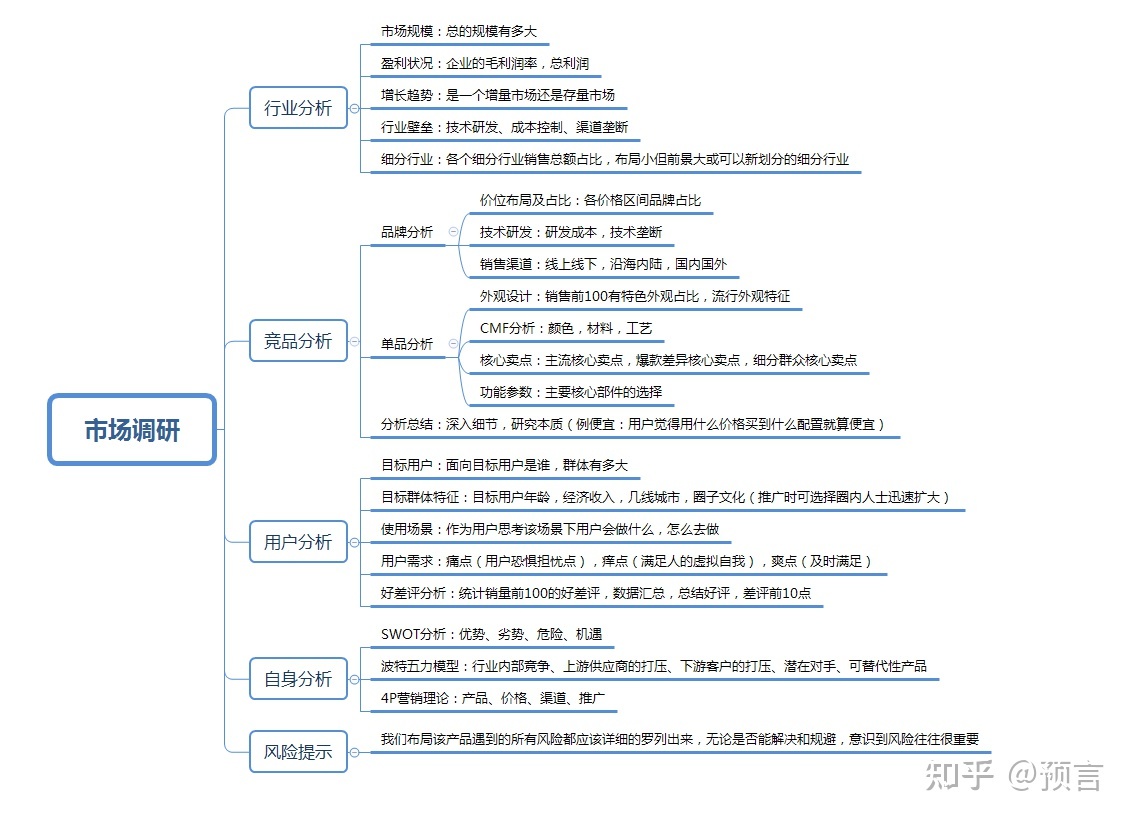
如何做好市场调研和用户需求分析报告?
在做市场调研和用户需求报告分析之前,我们应该明确我们调研的目的。如果你是一名产品设计类的学生,你可能更加以产品的外观和CMF为主。而如果你已经工作,你可能就要思考得更加深入,要清楚布局这个产品的目的和意义,深入思考这个产品在我们整个产品布局中的定位和作用大概是什么?是为了完善我们在各个价格区间的布局?还是巩固我们已有的某方面优势?是主要以走量为主?还是以赢取单个利润为主?等等这都是你要考虑的事情。而如果你是创业者,你就要更加注重研发成本,技术垄断,渠道扩展等方面。